Gerade in unserer zunehmend digitalen Lebenswelt ist es wichtig, dass Journalisten Informationen verarbeiten, in Kontext setzen und damit Bürgern eine Orientierungs- und Validierungshilfe in der Informationsflut bieten. Neben neuen journalistischen Werkzeugen brauchen sie auch rechtliches Know-how – zum Beispiel beim Web-Scraping.
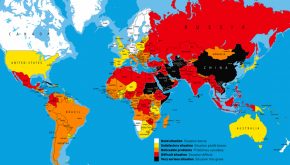
 Web-Scraper sind Programme, die Daten von Webseiten „abkratzen“, zum Beispiel Flugpreise von Airline-Seiten, um diese auf Vergleichsportalen anzuzeigen. Auch Daten für interaktive Karten können so generiert werden, die z.B. die Entwicklung der Corona-Pandemie darstellen. Es ist also eine Methode, um eigene Datensätze zu erstellen. Auch für Journalistinnen und Journalisten wird diese Methode immer relevanter, denn gerade die Verknüpfung von verschiedenen Daten kann zum Erkennen von neuen Mustern, Trends oder Missständen führen. Darüber hinaus gibt es immer mehr öffentliche Daten: Einerseits, weil wir als Gesellschaft immer mehr davon online produzieren, anderseits veröffentlichen Behörden verstärkt Daten selbst, zum Beispiel durch das Transparenzportal in Hamburg oder das Statistische Bundesamt.
Web-Scraper sind Programme, die Daten von Webseiten „abkratzen“, zum Beispiel Flugpreise von Airline-Seiten, um diese auf Vergleichsportalen anzuzeigen. Auch Daten für interaktive Karten können so generiert werden, die z.B. die Entwicklung der Corona-Pandemie darstellen. Es ist also eine Methode, um eigene Datensätze zu erstellen. Auch für Journalistinnen und Journalisten wird diese Methode immer relevanter, denn gerade die Verknüpfung von verschiedenen Daten kann zum Erkennen von neuen Mustern, Trends oder Missständen führen. Darüber hinaus gibt es immer mehr öffentliche Daten: Einerseits, weil wir als Gesellschaft immer mehr davon online produzieren, anderseits veröffentlichen Behörden verstärkt Daten selbst, zum Beispiel durch das Transparenzportal in Hamburg oder das Statistische Bundesamt.
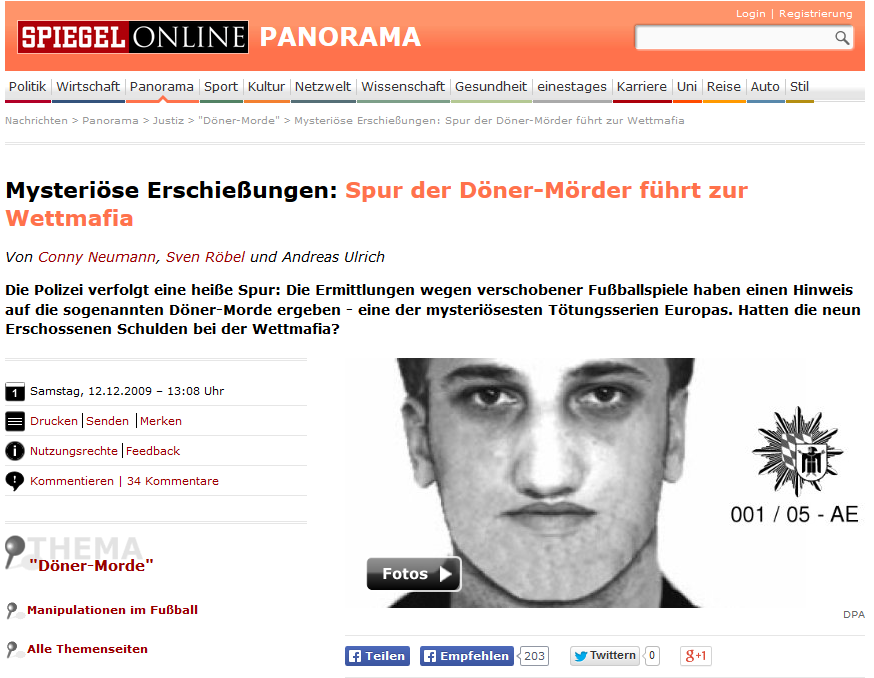
Damit gewinnt der Datenjournalismus an Bedeutung, denn die Daten zu beschaffen und zu analysieren erfordert zunehmend Kenntnisse in Statistik und Informatik. Zahlreiche Medienunternehmen fokussieren sich darauf und so werteten zum Beispiel der Spiegel und der Bayerische Rundfunk Schufa-Daten von 2.000 Verbraucherinnen und Verbrauchern aus. Damit konnten sie Kriterien der geheimen Schufa-Formel enthüllen.
Das Web-Scraping ist rechtlich kompliziert, weil die zwei Schritte, die man dafür benötigt – der Datenzugang und die Datenvervielfältigung – unterschiedliche Rechtsgebiete betreffen können. Es gilt nämlich die grundsätzliche Regel: Je nach Datenzugang oder Datentyp haben die jeweiligen Rechteinhaber bestimmte Rechte, die Nutzung der Daten einzuschränken, es sei denn eine Ausnahmeregelung greift. Eine solche Ausnahmeregel für Journalisten im Urheberrecht ist zum Beispiel § 50, der erlaubt, dass Ausschnitte für die Tagesberichterstattung verwendet werden dürfen.
Bei den zwei rechtlich relevanten Schritten des Web-Scraping muss daher im ersten Schritt darauf geachtet werden, dass der Datenzugang zur Ursprungsquelle rechtmäßig ist, zum Beispiel, dass es öffentlich zugängliche Daten sind oder vertragliche Vereinbarungen zum Scrapen getroffen wurden. An einigen Stellen könnte die Definition von „öffentlich zugänglichen“ problematisch sein, bspw. ob das Recht zu lesen auch das Recht, Text- und Data Mining vorzunehmen, beinhaltet (siehe „The Right to Read is the Right to mine“). Auch bei Messenger-Chats, an welchen Hunderte teilnehmen, stellt sich die Frage, ob Daten von „semi-öffentlichen“ Gruppen öffentliche oder private Daten sind. Handelt es sich bei der zu scrapenden Datenquelle um eine Datenbank, haben deren Hersteller spezielle Rechte, womit weitere Ausnahmeregelungen verknüpft sind. Ergo: Bereits der Datenzugang muss genau betrachtet werden.
Zusätzlich könnte das Web-Scrapen auch schon in den Allgemeinen Geschäftsbedingungen (AGB) verboten sein. Hierzu gibt es mindestens zwei relevante Urteile: 2015 entschied der Europäische Gerichtshof, dass die AGB ausschlaggebend seien, sofern eine Airline-Webseite keine Datenbank sei. Sonst würde das Datenbankenrecht mit den entsprechenden Rechten für die Herstellergreifen. Entsprechend mussten die niederländischen RichterInnen entscheiden, ob eine Airline-Webseite eine Datenbank darstellt. In Deutschland entschied der Bundesgerichtshof bereits 2014, dass Screen-Scraping von Flugpreisen für ein Vergleichsportal möglich sei, weil es der Verbrauchertransparenz diene. Sofern das Screen-Scrapen einer normalen Nutzung nicht zuwiderlaufe, handele es sich um kein unlauteres Verhalten – auch nicht, wenn entgegenstehende AGB ignoriert würden – so die damalige Rechtsprechung. Anders wäre es beim Umgehen von technischen Schutzvorrichtungen. Die zwei Entscheidungen zeigen ein unterschiedliches Vorgehen in den verschiedenen EU-Mitgliedstaaten, jedoch wären gerade beim Datenzugang und der Datenvervielfältigung europäische Regelungen wünschenswert, da sonst die nationalen unterschiedlichen Regeln zu mehr Rechtsunsicherheit führen und die Entwicklungen hemmen.
Im zweiten Schritt geht es um die jeweiligen zu scrapenden Datentypen. Handelt es sich um personenbezogene Daten wie Name oder Alter, ist die seit 2018 in der ganzen EU geltende Datenschutz-Grundverordnung heranzuziehen. Sie besagt, dass Daten ohne Einwilligung nicht genutzt werden dürfen – so auch der Rat für Sozial- und Wirtschaftsdaten. Trifft dies nicht zu, muss eine Abwägung zwischen den Interessen des Web-Scrapers und des Betroffenen vorgenommen werden (Artikel 6). Gerade also bei der Verknüpfung verschiedener Datensätze und Datentypen ist Vorsicht geboten.
Auch Bilder, Texte oder Videos könnten zu scrapende Daten sein, womit unter Umständen das Urheberrecht Anwendung findet. Auch hier gilt die Grundregel: Rechteinhaber müssen gefragt werden, es sei denn eine Ausnahmeregel greift. In Deutschland gibt es seit 2018 eine Text- und Data Mining-Ausnahme für nicht-kommerzielle Forschung, d.h. Wissenschaftlerinnen und Wissenschaftler können automatisiert urheberrechtliche Daten vervielfältigen und auswerten. Jene Ausnahme gilt jedoch nicht für Journalistinnen und Journalisten – sie können von dieser Ausnahme nur in Kooperationen mit nicht-kommerzieller Forschung profitieren. Zu dieser wissenschaftlichen Ausnahmeregel kommt jedoch noch eine allgemeine Ausnahmeregel für Text- und Data Mining mit kommerzieller Absicht zukünftig hinzu: Seit in Brüssel 2019 die Urheberrechte-Richtlinie verabschiedet wurde, haben die EU-Mitgliedstaaten zwei Jahre Zeit, diese Regeln in nationales Recht umzusetzen. In Deutschland gibt es dazu einen Entwurf, der vorsieht, dass die automatisierte Vervielfältigung von Daten erlaubt ist, um Muster oder Korrelationen zu erkennen – sofern ein rechtmäßiger Zugang besteht. Rechteinhaber können diese Nutzung nur in maschinenlesbarer Form untersagen. Wer Web-Scraping also ausschließen möchte, muss maschinenlesbare Schutzmaßnahmen zukünftig implementieren.
Auch wenn Text- und Data Mining-Ausnahmen Einzug in das Urheberrecht genommen haben und auch weitere Reformierungen versuchen, diese verschiedenen Interessen auszubalancieren, gibt es noch einiges zu tun. Insbesondere das Verknüpfen verschiedener Datensätze kann diverse weitere Rechtsgebiete wie Datenschutz, Urheberrecht oder Vertragsrecht betreffen. Gleichwohl ist es ein guter Zeitpunkt über neue Regeln zu diskutieren, denn die Datenbanken-Richtlinie wird derzeit reformiert und zudem schlug im Dezember 2020 die Kommission ein umfangreiches gesetzliches Paket vor, um die Verantwortung von großen Plattformen neu zu regeln. Wir befinden uns also erst am Anfang einer politischen Debatte. Journalistinnen und Journalisten erfüllen eine öffentliche Aufgabe, indem sie informieren, kontextualisieren und Missstände aufdecken – auch anhand von Datensätzen. Deshalb benötigen wir klare Regeln im Interesse der Unternehmen, des Individuums und der Gesellschaft.
Bildquelle: pixabay.com
Schlagwörter:Daten, Datenjournalismus, Datenschutz, Urheberrecht, Vertragrecht, Web-Scraping